SMELL is an Innosuisse project undertaken with collabration with the company Firmenich. The goal of the project is to develop a data-driven methodology which will allow us to uncover the olfactory perception mechanisms related to perfume creation and exploit them to build rational solutions that improve product performance and differentiation. We designed and developed novel machine learning algorithms that exploit side information to reliably predic olfaction of the product and exploit the similarities of ingredients with respect to olfaction.

Every bottle of perfume is a pool of data. Not only we can describe a specific type of perfume with a set of data that precisely describe its ingredients, but also the smell of that perfume can be put into a form of a vector that describes the strength of the main odors it contains. This movtivates to learn a model that can model the smell of a perfume from its formula that precisely describes the ingredients which it is made from. With the data and experties knowleage that our industry partner provides, we were able to develp a nonlinear model that can predict olfaction of perfume from its formula up to expert (perfumer, NOSES) level accuracy.

To build such a model, we also exploit the ingredients/molecules intrinsic property information to regularize the learned model. Such regularizer relies on a similarity matrix which we define on the ingredients space. We also developed a model that learns to filter out the false similarity of ingredients. Exploring the similarity of ingredients in the context of olfaction will help the industry partner to identify and replace some ingredients that are expensive and hard to find/synthesize. Our future vision is being able to reverse our prediction model where we can produce perfume formulas for a user-defined olfaction effect.
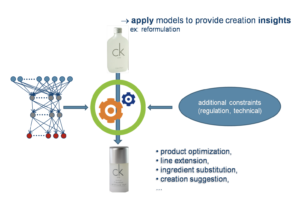
Results at a glance:
We have developed ML models that are able to predict the odour of a perfume by representing the perfume either in terms of the ingredients in consist of or the molecules that it includes. The developed models, utilising feature side-information (ingredient/ molecule chemical and physical properties), have shown great improvement over baselines which do not make use of such informations. The proposed concepts are applicable to various different setting, such as perfume or drug discovery.
Publications related to this project:
- Regularizing Non-linear Models Using Feature Side-information. http://proceedings.mlr.press/v70/mollaysa17a.html
- Learning to Augment with Feature Side-information. http://proceedings.mlr.press/v101/mollaysa19a.html
More to explore:
Automating the work of perfumers is getting more and more attention. Similar works are being proposed by various academic and industrial research center. The following link provides one such example.